Chapitre 3 : NORME JPEG>>compression jpeg
Transformée DCT
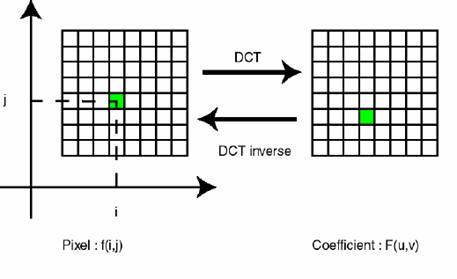
C'est le fait d'appliquer une transformée en cosinus discret à un bloc de pixels pour retirer la redondance des données de l’image.
Jusqu’à présent, on a juste
divisé l’image en sous-blocs de 8x8 pixels, transformé le mode de
couleur en YUV ou YCbCr et appliqué un sous-échantillonnage sur les
composantes de la chrominance.
Maintenant on va appliquer la DCT (Discrete Cosine
Transform, ou bien transformée en cosinus discrète en français).
La DCT est
une variante de la transformée de Fourier. Elle a pour but de
regrouper l’énergie en passant de la notion de pixels et couleurs à
la notion de fréquences et amplitudes. En effet, elle prend un
ensemble de points d'un domaine spatial et les transforme en une
représentation équivalente dans le domaine fréquentiel. Dans notre
cas, on étudie une image couleur, c'est à dire qu’il sera traité
trois fonctions (de manière indépendantes) à 3 dimensions : X et Y,
indiquant le pixel, et Z avec la valeur du pixel en ce point. Ces
trois fonctions correspondent chacune à un des canaux RVB. Après
l’application de cette transformée sur un bloc, on va avoir
l’information essentielle stockée dans les basses fréquences
(luminance) et l’énergie sera regroupée en haut à gauche de la
matrice. Pour ce qui est des hautes fréquences (chrominance), on les
retrouve en bas à droite de la matrice, plus on approche du bas
droite de la matrice plus leurs coefficients tendent vers 0.
Cette transformée va être appliquée à chaque composante pour chaque
bloc. En effet, pour une image codée sur 24bits, on va appliquer la
DCT 3 fois sur chaque bloc (1 pour la composante Y, 1 pour Cb ou U
et 1 pour V ou Cr).
La DCT s’exprime mathématiquement comme suite :

p (x,y) est la valeur du pixel aux coordonnées (x,y)
Ce qui donne dans notre cas (bloc de 8x8 pixels):
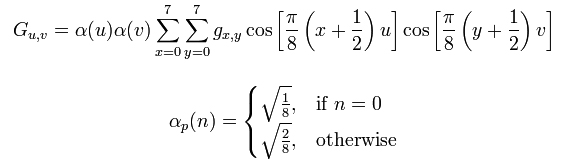
gx,y : La valeur du
pixel aux coordonnées (x,y).
Gu,v : La valeur de la DCT aux coordonnées (u,v).
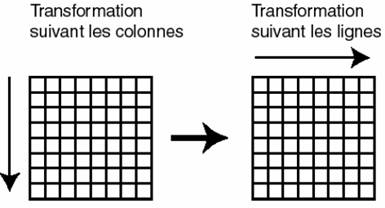
La transformation DCT est en fait une décomposition d’une image en plusieurs sous-images de bases (fonctions de bases). Dans notre cas, on va utiliser la transformation DCT dite 2 dimensions. En effet, la transformation se compose d’une transformation suivant les colonnes et une transformation suivant les lignes :
Le schéma suivant montre les différentes 64 sous-images produites par la DCT :

Avant d’appliquer la DCT, on doit faire une petite transformation au niveau des matrices. En effet, pour un pixel codé sur n=8 bits, on doit soustraire à chaque valeur 2n/2 =128 et ce pour passer de l’intervalle [0,255] à l’intervalle [-128,127] (mettre à zéro la gamme des valeurs). Après l’application de la DCT, on arrondit les nombres pour avoir des entiers.
La DCT doit être appliquée à des matrices carrées et plus précisément des matrices 8x8 tout simplement parce qu’il y aura moins de calculs et donc du temps sera gagné. En effet, pour une matrice 8x8, si l’on veut calculer un coefficient de la DCT Gu,v , 8*8=64 additions seront effectuées tandis que pour une matrice 1024x1024, 1024*1024*=1048576 additions seront nécessaires, ce qui est énorme pour calculer 1024*1024 coefficients..
L'objectif principal de cette étape est d'obtenir une nouvelle représentation de chaque bloc contenant la même information et cette information concentrée sur peu d'éléments et c’est l’étape qui coûte le plus de temps mais elle est très importante puisqu’elle nous permet de séparer les basses fréquences et les hautes fréquences.